
CUSTOMER
The customer is one of the leading developers of enterprise resource planning and business automation solutions.
CHALLENGE
The customer daily deals with huge data amounts and their analyzing. So the task was to create a tool that can aggregate and analyze data from various sources in real time. The main challenge in the same time was to develop a uniform interface for presenting heterogeneous data and to ensure their mixing from various sources without prior unloading into a special intermediate storage. And, what is more important, to present this solution in a language understandable to business users.
SOLUTION DESCRIPTION
After analyzing all the above challenges, GalaktikaSoft team identified ways to effectively solve the problem of mixing data from different sources. We also prepared layouts of visual designers for working with metadata of physical sources, and made their presentation in terms understandable to the end user.
GalaktikaSoft experts created a technological prototype for working with data in real-time called Ranet DataKit. This is an analytics module with the Self-Service function, and the ability to adapt to specific business tasks for real-time data analysis quickly. We chose the Apache Drill platform as the core for building our solution.
KEY FEATURES:
- Provides single view of any data sources based on the relational data model (schemas, tables, columns, associations)
- Speaks on the end-user language: business terms for the business users
- Embedded, user-friendly, visual designers of data schemes and query views
- Support for any data source (using Apache Drill features)
- Virtual data sources obtained by mixing or combining data from different sources, federated queries
- Unified settings repository that describe logical virtual data sources
- Unified storage of settings and services
- Cross-platform client support
- API for integration into third-party solutions and applications (including direct work with the View Drill)
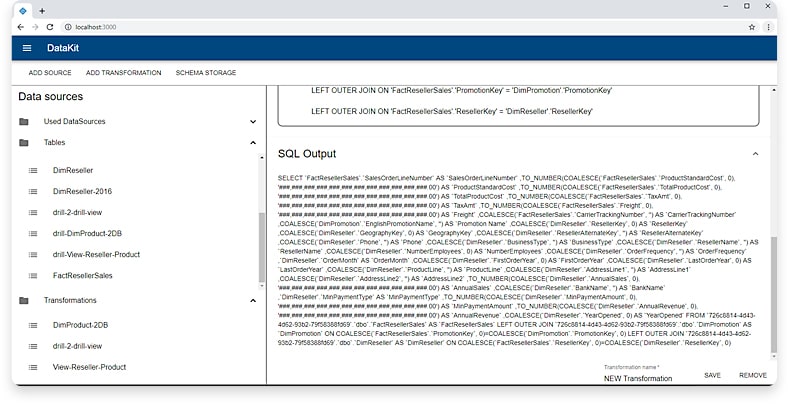
SYSTEM DEVELOPMENT
The main difficulties were to deal with:
- Developing mechanism for the unified transformation of data from physical sources into logical virtual data sources in terms of a business user (mixing different data sources)
- Implement federated queries (retrieving data from various sources in one query)
Analyzing existing difficulties and system’s characteristics important for the users, we developed the following functional specification:
| Physical data sources management |
|
| DataKit Schema Designer | Creating a logical virtual data source:
Transformations and Views creation:
|
| DataKit schema storage |
|
| Administration utility |
|
Then, the solution was implemented as a client-server application where:
- Server side: nodeJS + ExpressJS
- Client side: React + Material-UI
Data storage schema implemented in files and automatic build is in Docker image containers that allows you to use any OS as a carrier.
The Ranet DataKit prototype functions in a virtualization environment using:
- Web Server DataKit: application server, unified storage, scheduling user requests. MongoDB database is used to store configuration metadata.
- Apache Drill: execution of data requests, including federated ones. It operates in a distributed cluster environment on Hadoop and includes 4 nodes on virtual machines to provide the necessary performance. Apache Drill Web Console can be used to administer and monitor requests.
As a result, we have implemented:
- End-to-end logging and control of all errors with the record in a system log;
- Traffic compression during communication + client identification by tokens + authentication with the ability to connect external services during communication + client identification by tokens + authentication with the ability to connect external services;
- Session control and multiuse;
- Ability to localize in any language;
- Full load balancing and wide scaling. The cluster increases the capacity by launching new nodes, if the capacity is not used the extra nodes are removed. At the same time, the system is available 24/7.
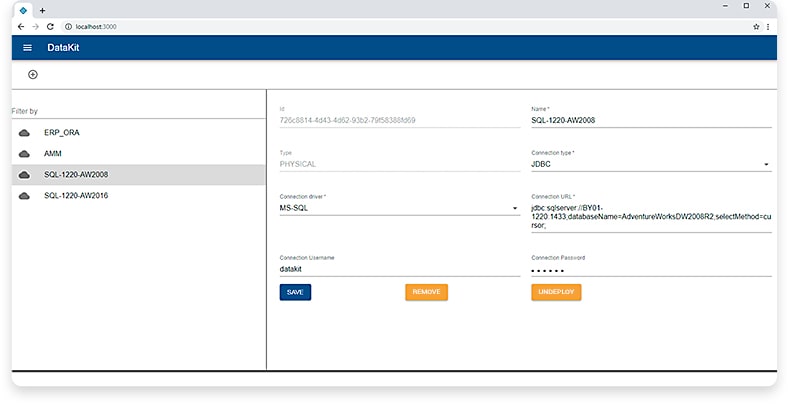
HOW DOES IT WORK?
The system administrator determines the physical data sources (databases of OLTP systems, Excel, JSON and other files, etc.), in the analysis of which specific business users are interested. Then administrator configures connections to physical data sources and publishes settings on the Apache Drill server. Relational model (schemas, tables, columns, associations) allows you to create a unified representation of data from different sources.
In the next step the administrator in a special visual designer models Perspective - a virtual data source scheme, expanding the physical source schemes with custom types, if necessary, adapting metadata to the requirements of business task. In fact, at this stage, the scheme of the physical data source is translated into a language understandable to business users and the rules for linking and transforming data are configured. Thus, the scheme that describes the logical virtual data source is generated.
For the views design we utilized WYSWIG-designer. The visual designer has a friendly interface and available for both the system administrator and end-user business users. The end-users can refine Perspective and View created by the system’s administrator, taking into account new tasks, their own working style, terminology, etc. This provides interactive data analysis.
Views can be published to the Apache Drill server, and reused when creating new ones. Ranet DataKit will have a universal software interface. This will allow the service to be integrated into other applications as a universal data source. In addition, views published on the Apache Drill server can be accessed directly, bypassing the DataKit server.
RESULT
As a result, we get the tool, which provides:
- Any data - in business terms that correspond to the professional language of the end users.
- Federation of data and federated queries - the ability to combine heterogeneous data sources in one query.
- Interactive analysis of the most up-to-date information, independent of ETL processes and other tools for data mining and processing.
- Work with relevant information - storage data and raw data.
- Low threshold of entry: interactive, user-friendly WISYWIG designers.
- Universal API for integration into third-party solutions.
Completing assigned task, all this will also accelerate the company's response to external and internal changes based on interactive analysis of data from all available sources.
TECHNOLOGIES
Linux, Hadoop, Apache Drill, Apache ZooKeeper, Node.js, Express.js, React, MongoBD, Docker.
