

Without what thing is impossible to imagine your life today? I suppose, the top answer will be Google. Data and the need for new info rule our life that is why Google is a real rescue. Using Dremel technology, it manages big data every second to provide us with an efficient search source, YouTube, Docs and other.
The same situation happens with BI world. Imagine a data analyst trying to sort and analyze huge unstructured data amounts himself. It will take 100% of his time. That is why big data tools are reliable support in it. And Apache Drill is one of them.
What is Apache Drill?
As you’ve already understood, our today’s star is Apache Drill. So let’s together explore this popular tool, starting with its characteristics.
Definition
Apache Drill is an SQL query engine designed for a large amount of data processing. It was designed to support high-performance analysis and restructuring of Big Data coming from modern applications.
Initially Apache Drill was inspired by Google Dremel, mentioned in the introduction. Drill acts as an intermediary that allows you to request self-describing data using standard SQL.
Architecture
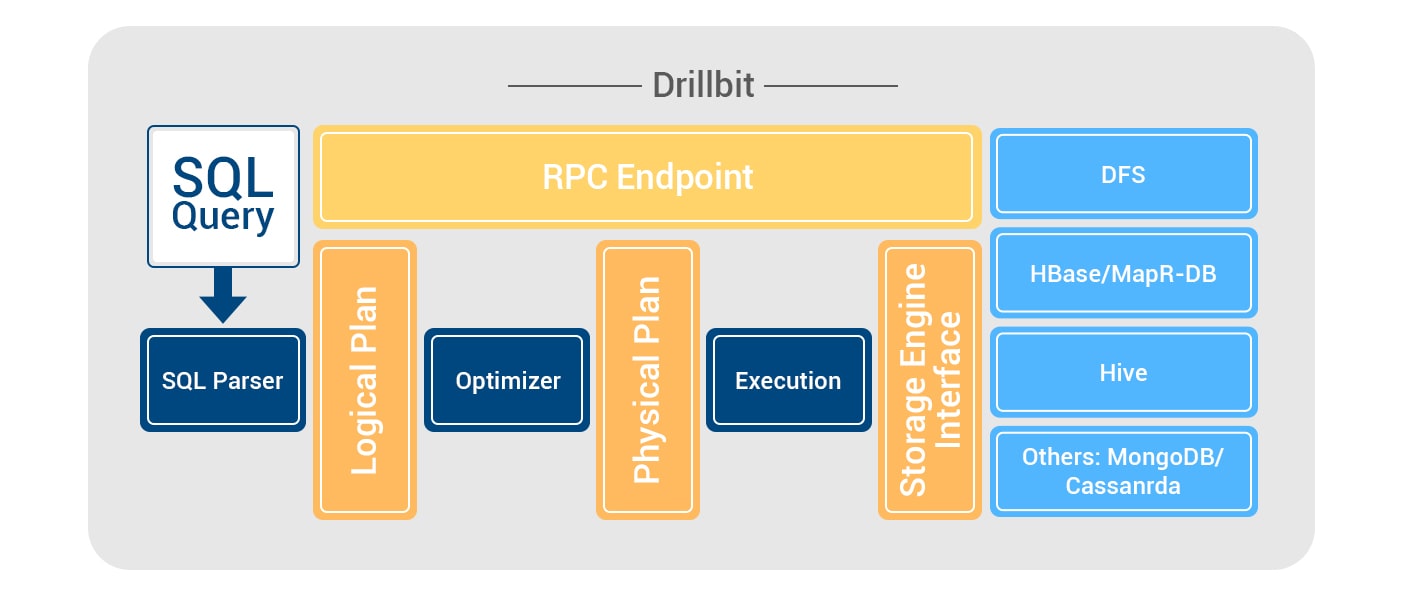
Drill includes a distributed execution environment for large-scale data processing. The Apache Drill is based on the Drillbit service, which is responsible for receiving requests from the client, processing them and returning results.
The Drillbit service can be installed and run on all required nodes in a Hadoop cluster to form a distributed cluster environment. When Drillbit runs on every data node in a cluster, Drill can maximize the data location during query execution, without moving data across the network or between nodes. Drill uses Apache ZooKeeper to maintain cluster membership and performance checks.
Apache Drill architecture characterized by four main features:
- Dynamic pattern recognition
- Flexible data model
- Extensibility
- Non-centralized metadata
Peculiarities
What are the special Drill features? There are 3 following peculiarities Apache Drill has:
- No centralized metadata storage system. They are delivered from plugins that send a request to the repository: complete, partial, and decentralized information. It is possible to make requests to several nodes, to collect information from their child branches or files.
- Does not require a data schema or storage format specification for query execution. Some formats, such as Parquet, JSON (JavaScript Object Notation), AVRO, and NoSQL DB contain a description of the data storage format inside, which allows Drill to compute this dynamically. Since the data scheme in the request may change, many commands are designed to reconfigure them.
- Supports many non-relational databases and file systems including HBase, MongoDB, MapR-DB, HDFS, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS, as well as local files. One request can include data from multiple repositories. For example, you can combine user information in MongoDB with the event log directory from Hadoop.
Why is it useful?
What makes Drill so popular? Of course, there are some proof reasons and here are they:
| Start working at once | Just a few minutes and you are working with Drill. As there is no need to define schemes and infrastructure in advance. Just unzip the Drill program on your computer or laptop, query the local file and simply point to data in a file, directory, HBase table, or drill. |
| Query almost any NoSQL database | Apache Drill supports MongoDB, HBase, MapR-DB, MapR-FS, HDFS, Amazon S3, Azure Blob Storage, NAS, Google Cloud Storage, Swift and local files. Besides, one query can merge data from multiple data stores. |
| Standard SQL syntax | As Drill supports a standard SQL language there is no need to learn other SQL-like languages and use a semi-functional BI tool. |
| Keep using a habitual BI tool | Business users can use standard BI tools, such as Tableau, Qlik, Spotfire, MicroStrategy, SAS, and Excel, to interact with non-relational data stores using Drill JDBC and ODBC drivers. Developers can use the simple REST API Drill in their user applications to create beautiful visualizations. Drill virtual datasets allow you to display even the most complex non-relational data into BI-friendly structures that users can explore and visualize with preferred tool. |
| The only columnar query engine supporting complex data | It implements a fractional columnar representation in memory for complex data, which allows Drill to achieve columnar speed due to the flexibility of the internal model of the JSON document. |
| 2 in 1 | Thanks to the architecture that delivers record-breaking performance without compromising the flexibility offered by the JSON document model, Drill provide high speed and flexibility at once. |
How does Apache Drill work?
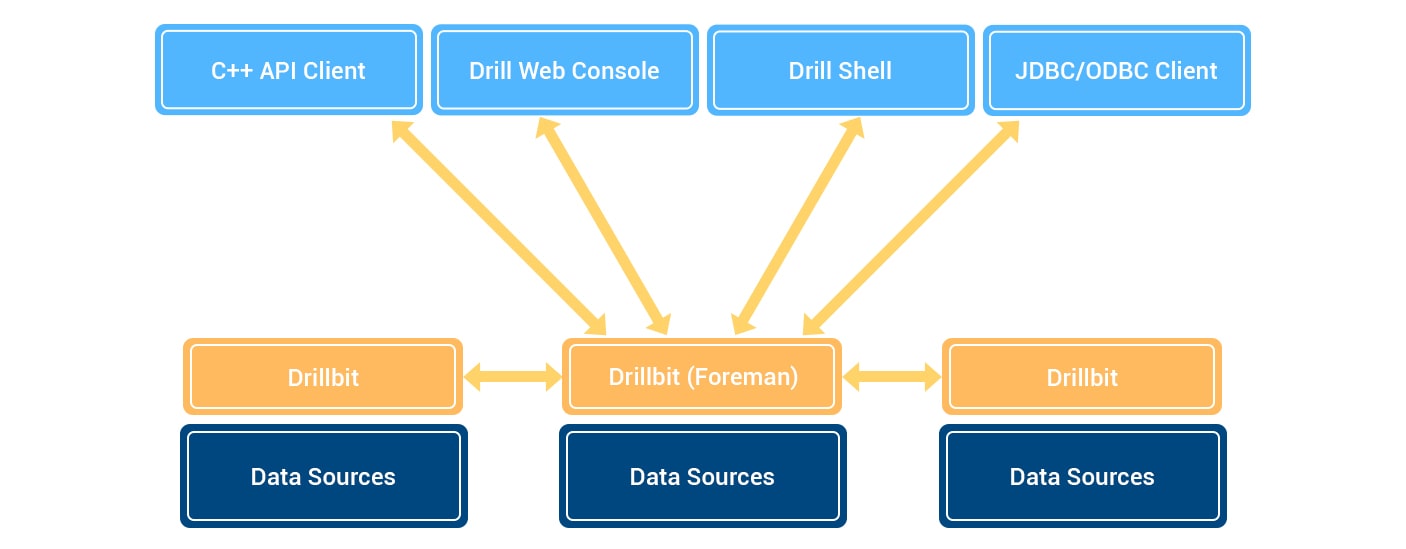
Let’s learn it in some details. The client or application sends an SQL request to the Drillbit in the Drill Cluster. Drillbit is a process running on each active Drill node that coordinates, schedules and executes queries, and also distributes query work in a cluster to maximize data locality.
Drillbit receives a request from a client or application and thus becomes Foreman for the request and manages it. The parser in Foreman analyzes SQL, applying special rules to convert certain SQL statements to a specific logical operator syntax that Drill understands. A set of logical operators forms a logical plan. It describes the work needed to generate the query results, and determines which data sources and operations should be used.
Foreman sends a logical plan to a cost optimizer to optimize the order of SQL statements. The optimizer applies various types of rules to rearrange the operators and functions in the optimal plan. It then converts the logical plan into a physical plan that describes how to execute the query. Foreman's parallelizer breaks the physical plan into a primary and secondary fragment. These fragments create a multi-level tree that rewrites the query and runs it in parallel with the configured data sources, sending the results back to the client or application.
Some terms:
Primary fragment
The primary fragment is a concept that represents the stage of request execution. Each stage can consist of one or more operations that the Drill must process to fulfill the request. Each primary fragment is assigned a MajorFragmentID. Drill uses the swap operator to separate the primary fragments.
Exchange is a change in the location of the data and / or parallelization of the physical plane. Primary fragments do not actually perform any tasks. Each primary fragment is divided into one or several secondary fragments that actually perform the operations necessary to complete the request and return the results back to the client.
Secondary fragment
The secondary fragment is a logical unit of work that is performed within the stream. The logical unit of work in a Drill is also called a slice. Drill assigns each secondary fragment a MinorFragmentID. Foreman's parallelizer creates one or more secondary fragments from the primary fragment at runtime, breaking the primary fragment into as many small fragments as it can usefully run simultaneously in a cluster.
Secondary fragments contain one or more relational operators that perform one of such operations as scanning, filtering, merging, or grouping. Each operator has a specific operator type and OperatorID. The ID defines the relationship of the secondary fragment and the operator.
Are there any similar solutions?
As the technology is so promising the logical question now: are there any other similar products? What else can the market propose? Is it possible to get even better results? Of course. Constantly growing and competing market inspires the software development companies to create new, fresh and innovating solutions. And GalaktikaSoft is not an exception.
GalaktikaSoft created a technological prototype of the future decision to work with real-time data Galaktika DataKit with the core of the Apache Drill engine.
The Galaktika DataKit solution is designed as a Self-Service Business Intelligence that has a user-friendly interface and is able to perform analytical tasks formulated in business terms familiar to the average user.
How does it work?
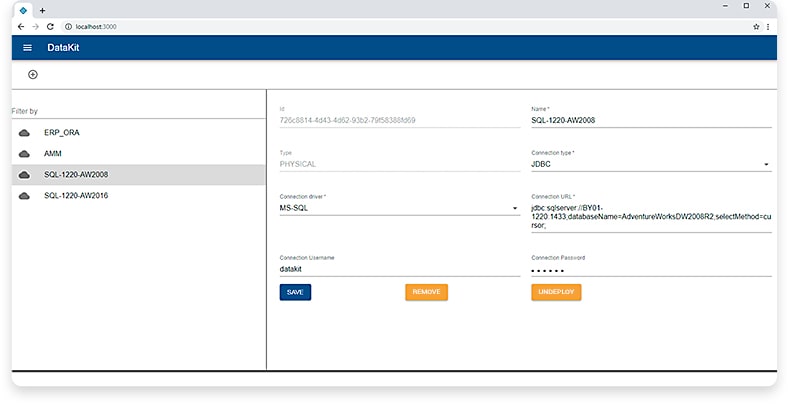
The system administrator determines the physical data sources that specific business users want to analyze. These can be databases of OLTP systems, Excel, JSON and other files, etc. The administrator configures connections to physical data sources and publishes settings on the Apache Drill server. Using the concepts of the relational model (tables, columns, associations) allows you to create a unified representation of data from different sources.
Then, the administrator using special visual designer models Perspective - a virtual data source scheme, expanding the physical source schemes with custom types, if necessary, adapting the metadata to the requirements of the business task.
In fact, at this stage, the scheme of the physical data source is translated into a language that business users can understand and the rules for linking and transforming data are configured. As a result, the views are formed, requests to data sources in ANSI SQL.
The views can be published to the Apache Drill server and reused, when creating new ones.
Key features
DataKit provides the following capabilities:
- Any data presented in business terms that correspond to the professional language of the end users;
- The ability to combine heterogeneous data sources in one query;
- Interactive analysis of the most up-to-date information, independent of ETL processes and other tools for data mining and processing.
- Work with today's and tomorrow's storage data and “raw data”;
- Low threshold of entry: interactive, user-friendly WISYWIG designers.
- Universal API for integration into third-party solutions.
All those benefits will speed up the response of enterprises to external and internal changes based on interactive data analysis from all available sources.
Summary
The data is our everything. And every day it becomes more and more. That is why, it is almost impossible to imagine the life of a modern business manager or analyst without IT tools, which can aggregate and analyze data from different sources in real time.
Such tools as Apache Drill and Galaktika DataKit provide such opportunity. The key feature gives the ability to combine data from different sources in one request. Organize federated requests for data sources. At the same time, there is no need for a preliminary definition of data schemes: they are formed on the fly. Apache Drill allows you to process large data in a distributed Hadoop cluster environment.
In other words, try yourself and be aware, those tools will make your life easier.
